Ask Claude whether you should learn Python or JavaScript first, and it will refuse to pick. It hands you a fork: Python if you want data, automation, or AI work, JavaScript if you want to build websites, and a note that you’ll end up learning both anyway. Ask the exact same question again, but add five words to the end of it, “Answer in one short sentence,” and the fork is gone. “Learn Python first,” it says now. It picked a side it had declined to pick about thirty seconds earlier.
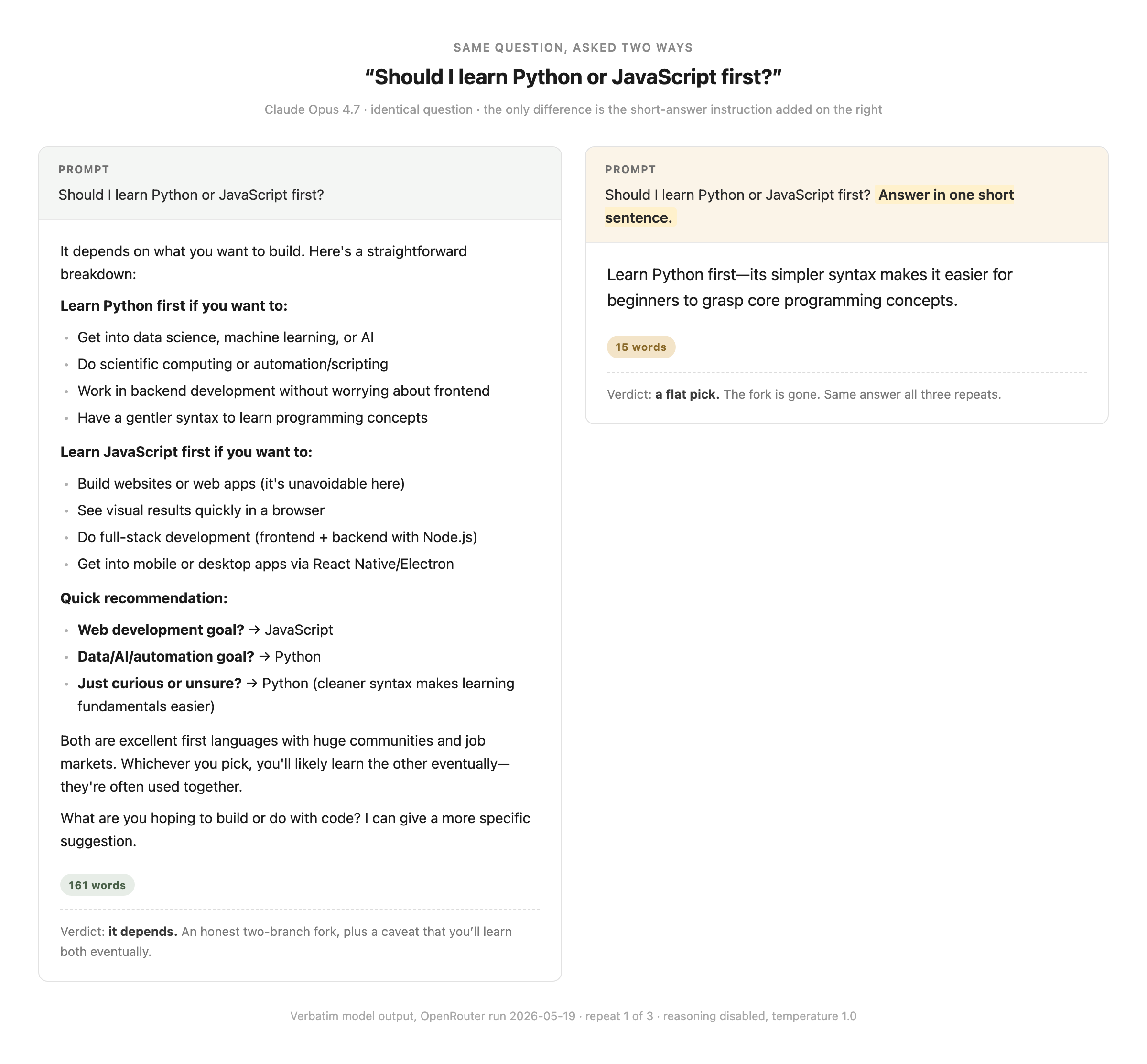
Nothing about the question changed. The reader’s goals didn’t change, the facts about the two languages didn’t change. Five words about length changed the answer. To see why a length instruction can reach that far, you need one fact about how the answer gets made in the first place. It’s a small fact, and once you have it, three things you’ve probably noticed about AI chat stop being mysterious.
The answer is built, not retrieved
The picture most people carry around is that the AI knows the answer, and the spinner and the streaming text are just the delivery, the model fetching a finished thing and handing it over. That isn’t what happens. The model doesn’t have the answer anywhere. It writes the answer the way you’d write a sentence you’ve never said before: forward, one piece at a time, with no copy of the finished thing to consult.
Here’s the actual loop. The model looks at everything written so far, which at the start is just your question, and produces a probability for every word that could come next. 3Blue1Brown, in a short general-audience explainer, describes a language model as “a sophisticated mathematical function that predicts what word comes next for any piece of text,” one that “assign[s] a probability to all possible next words.” The model picks one. Then it adds that word to the text and runs the whole thing again, now with one more word to condition on. Predict, append, repeat. The streaming text on your screen is that loop running, live, in front of you. You’re watching the answer get built, not watching a finished one get revealed.

One honest piece of vocabulary, then we can drop it. The model doesn’t strictly work in words. It works in tokens, which are word-chunks: “Python” might be one token, “JavaScript” might be two or three. “Word by word” is close enough to be the working picture, so we’ll keep using it. The point that matters is the shape of the loop, not the size of the pieces.
So the model is always writing into the unknown. When it produces the first word of an answer, it has not committed to the second, let alone the conclusion. And each word, once written, is locked. It becomes part of the input for the next prediction. There’s no draft, no revision pass, no moment where the model reads its finished paragraph and tightens it. Everything an AI has ever written, it wrote forward, and only forward.
Why an AI talks its way out of a mistake
That “locked once written” part has a visible consequence, and for a couple of years it was one of the most charming things about chatting with these models.
Picture the model answering a question about Australia. It writes “The capital of Australia is” and then, predicting one word at a time, lands on “Sydney.” Sydney is the famous city, it shows up constantly near the word Australia, and the probability machine reaches for it. But the capital is Canberra. A person catches this by deleting “Sydney” and typing the right word. The model can’t. “Sydney” is already written, already locked, already part of what it’s conditioning on. The only direction it has is forward. So it does the only thing it can: it writes its way out. “…is Sydney, or rather, Canberra.” The correction happens in the open because there’s nowhere else for it to go.
That stumble is the mechanism caught in the act. It’s the clearest possible proof that the model is composing live and can’t take a word back. Two or three years ago you saw it constantly. Forums filled up with screenshots of models contradicting themselves mid-paragraph; a 2023 Hacker News thread is full of people swapping examples of ChatGPT correcting itself in real time.
You see it less now, and the reason is worth knowing. Today’s reasoning models do their messiest trying-and-backtracking in a separate hidden step before they write the answer you see. The model catches its own Sydney-to-Canberra slip back there, where you can’t watch, and the visible answer comes out already clean. The behavior didn’t go away. Researchers still document models correcting themselves within a single response. It mostly just moved offstage. You can still catch the live version in a model’s fast or instant mode, or in an open model like DeepSeek that streams its raw working where you can read it. But in a normal ChatGPT window in 2026, the stumble usually happens where you’ll never see it.
What “keep it short” actually changes
It’s tempting to read “Answer in one short sentence” as a formatting preference, like asking for bullet points or a friendlier tone. The mechanism rules that out. The model commits to a path from the very first token. When the first word is the start of a fifteen-word answer instead of a hundred-and-sixty-word one, it has set off down a different road, and a shorter road doesn’t have room for the same scenery. You don’t get the long answer with the nuance trimmed off. You get a different, more compressed line of reasoning that never had the nuance in it.
A claim doing this much work has no business shipping on intuition, so I ran it. Four open-ended “it depends” questions: Should I learn Python or JavaScript first?, Is it bad for your health to eat salt?, Is it rude not to tip in a restaurant?, What time of day is best to exercise? Each one asked of GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 Pro, twice: plain, then with the literal string Answer in one short sentence. appended. Three repeats per pair. Ninety-six answers.
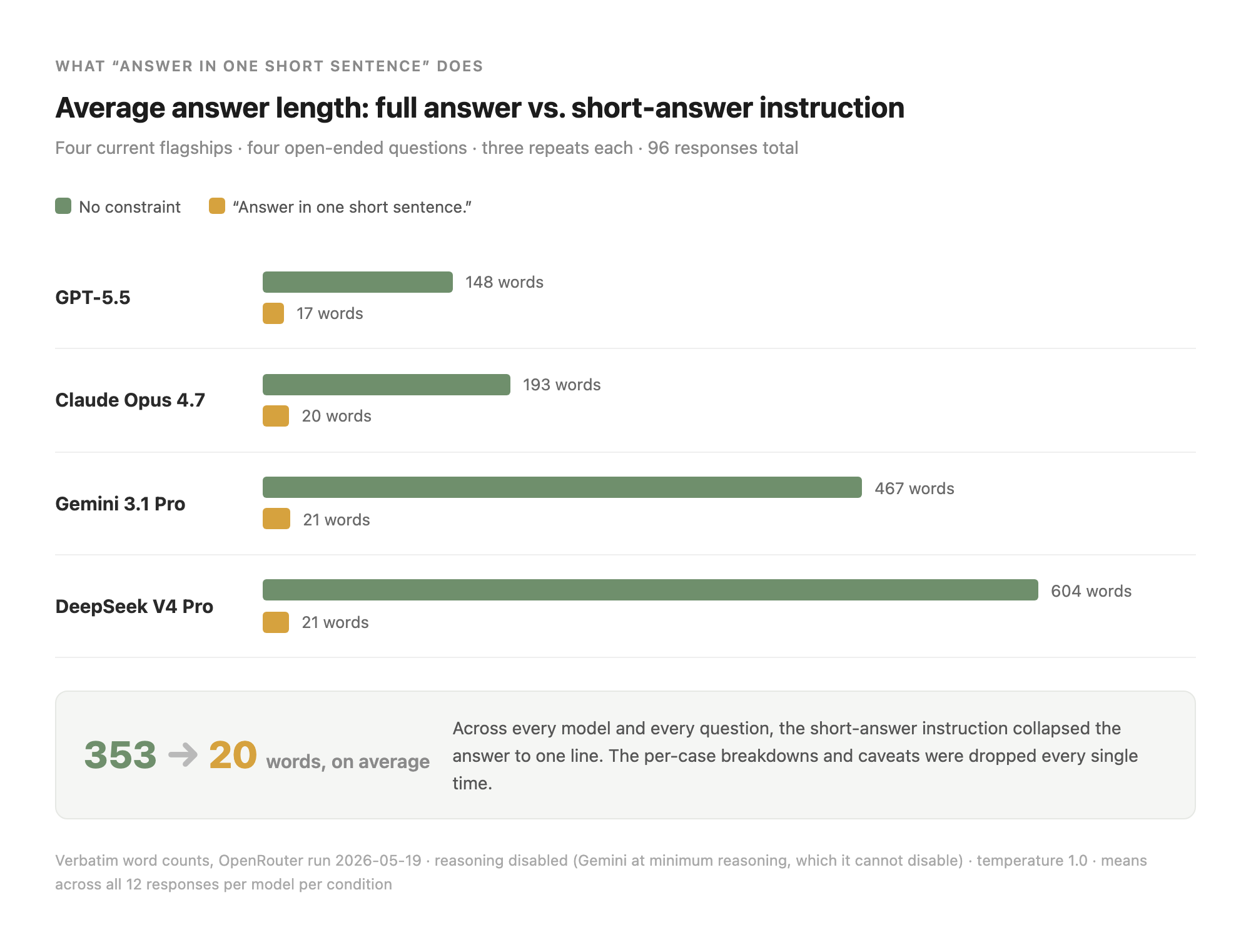
The compression showed up every time. The long answers had the same architecture: a stance, then a breakdown by case, then the nuance (“roughly 25 to 50 percent of people are salt-sensitive…”), then the caveats. The short ones kept the most central point and dropped the rest. Not “trimmed.” Gone, because the compressed path never built them.
The Python flip is the dramatic version, and it didn’t happen every time. Under “one short sentence,” GPT-5.5, Gemini, and DeepSeek mostly kept a squeezed-down fork (“Python if X, otherwise JavaScript”). Claude Opus 4.7 didn’t. Three times in a row, it dropped the fork and led with “Learn Python first.” A model forced to be brief picked a side it had specifically declined to pick.
This isn’t just our finding, which is the reassuring part. Giskard’s Phare benchmark, with Google DeepMind among its partners, found conciseness instructions degraded factual reliability across most models tested by up to 20 percent. An academic paper on short-path prompting found brevity requests destabilized reasoning “even on grade-school problems.” Read that 20 percent narrowly: it’s a drop in resistance to a specific kind of error on one benchmark, not “one in five short answers is wrong.” The useful point is smaller and sharper: brevity is a content decision wearing a length costume.
Practical version: if nuance matters, ask the long version first, then ask for a tight summary. The caveats are in the conversation for the summary to draw from. Asking for short on reflex and trusting you got the same answer, only tidier, is the trap. You got a different one, and you chose it without meaning to.
The long spinner is more words you can’t see
The spinner has a cleaner story than most people assume, and it comes in two honest parts.
When you hit enter, the model first has to read everything you’ve given it: your question, and the entire conversation above it, and any files you’ve attached. It does that reading in one fast parallel pass to get ready to write the first word. That’s the gap between pressing enter and seeing the first word appear. It grows with input, which is why a long conversation answers slower than a fresh one, and why a chat with three PDFs attached makes you wait longer before anything shows up. Then the second part: once words start streaming, you’re watching the writing itself, one token at a time, at whatever pace the model generates.
So there’s a usable little diagnostic in there. A long wait before any text appears is the model still reading and getting ready, or a busy server. Text that shows up quickly and then streams out slowly means the writing itself is the slow part. Two different waits, two different causes.

Except there’s a third cause now, and on a reasoning model it’s often the real one. Turn on a model’s thinking mode and the long spinner is the model writing a large batch of tokens you don’t get to see, a scratchpad where it works the problem out before it writes the answer for you. Not reading, not a slow server. The longer spinner is literally more words being written, just offstage.
What you see when you click to expand “Thinking” is usually not that scratchpad. On Claude, Anthropic’s own documentation explains that the thinking you’re shown is a summary “processed by a different model than the one you target in your requests,” and that “the thinking model does not see the summarized output.” A second model writes you a clean recap of the first model’s reasoning. ChatGPT has worked this way since its first reasoning models: you see a summarized chain of thought, not the raw one. The visibility keeps shifting, too. Claude Opus 4.7 stopped showing its thinking by default at all; it now decides for itself how much to think and shows you nothing of it unless you go looking. Gemini sits at the other end: you can’t switch thinking off at all. The model uses it on every question you ask.
That has a direct consequence for a habit a lot of people have. When you don’t like an answer and you ask the model “why did you say that?”, you are not getting a readout of the scratchpad. The scratchpad is summarized, or hidden, or already gone. The model answers “why?” the only way it can: by composing a fresh explanation, forward, one token at a time, built to fit the answer it already gave. A plausible story, generated now, not a replay of the actual reasoning. Which is the first of three habits worth keeping from all this.
Three things to do with this
The mechanism is one fact: built live, left to right, every word locked as it lands. Three habits fall out of it cleanly.
Ask for the reasoning before the conclusion, not after. If you want the model’s actual working, put the request in the prompt up front: “Work through this step by step, then give me your answer.” That makes the reasoning part of the live trajectory, generated before the conclusion exists, so the conclusion is conditioned on it. Asking “why?” after the answer gets you the fresh-story version instead, an explanation built to justify a verdict that’s already on the screen. Same question, very different reliability, and the only difference is which side of the answer you asked it.
Choose the short answer on purpose. When you want a fast gist on a low-stakes question, ask for short and enjoy it. When the nuance is the whole point, let the model take the long path first, then ask: “Now give me the one-sentence version.” The caveats are already in the conversation for the summary to draw from. Asking for brevity is fine. Asking for it without noticing you asked for something else too is what trips people up.
Know what “regenerate” actually does. You don’t get the same answer reworded. You get the model setting off from the first token again, and a different first token sends it down a different path, sometimes to a different conclusion. In our test, Gemini and DeepSeek each produced a run that opened with the other branch of the Python fork, “choose JavaScript first if…”, purely because a different early word pointed the sentence somewhere else. So for any question that matters, run it two or three times and read the spread. Treat that spread less as the model being unreliable, and more as the model showing you, for free, that there was never one answer waiting in there to come out.