In March 2026 someone went on Reddit and bet their house. The claim: ask ChatGPT to pick a number between 1 and 10,000, and it’ll land between 7,300 and 7,500 every single time. A thousand people upvoted. Seventeen hundred replied, most of them with their own results. As far as anyone in the thread could tell, the house was safe.
That post is gone now, the account deleted, but a Hacker News discussion of that post is still up. Two commenters compared notes there. One had asked Claude for a number in that range and gotten 7,342. The other replied that they’d also gotten 7,342. The same four digits, from the same prompt, on two different people’s machines, with no coordination at all.

You have probably bumped into a smaller version of this yourself. Ask an AI to pick a card and it reaches for a queen. Ask for a dog name and it offers Milo. The machine has favorites, and once you notice them you can’t stop. None of this is a glitch. It has a specific, well-understood cause rooted in how chatbots are built, and below are two prompts that work around it, each of them a single sentence you paste into a normal chat box. No settings, no code, no API.
A bet nobody could win
To see how deep this goes, we ran the obvious experiment. One prompt, “pick a random number 1 to 10,” twenty runs each, across the four current flagship models on their default settings: GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4. When we tested this in May 2026, the results were almost comically tidy.
GPT-5.5 said 7. Then 7 again. It said 7 all twenty times, with not a single other number in the set. Claude Opus 4.7 did exactly the same: twenty out of twenty, all sevens. Gemini 3.1 Pro and DeepSeek V4 both said 7 at least eighteen times out of twenty. The vegetable question was the same story. Three of the four models answered “carrot” eighteen to twenty times out of twenty, as if the other vegetables had been quietly removed from the building.



The unsettling part is not that one chatbot is predictable. It is that chatbots built by different companies, trained on different hardware, polished by different teams, all converge on the same answer. They picked 7. They picked carrot. They did it without conferring, and they did it because, in a sense, they all studied from the same notes. More on that shortly.
The collapse isn’t uniform, and the pattern in where it loosens is worth knowing. The narrower the question, the harder the convergence. “Number 1 to 10” has only ten possible answers and the models jammed themselves onto one of them. “Suggest a dog name” has effectively unlimited answers, and there the models loosened up, offering a handful of different names across twenty runs instead of one. Still a short list of favorites. Just a longer short list. And the sameness isn’t only a number problem, which the r/ChatGPT thread also caught: one commenter noted that if you ask an AI for a random fact, you have a decent chance of learning that octopuses have three hearts. Ask for anything open-ended and the machine reaches for the same drawer.
Why a chatbot has favorites
A chatbot is built in two stages, and the second stage is where the favorites come from.
In the first stage, the model reads an enormous amount of human writing and learns the range of how people answer things. If that were the whole story, asking for a number 1 to 10 would give you something close to the spread of numbers people actually write down, sevens included but not exclusively. The first stage learns variety.
Then comes the polishing. The raw model is shaped using examples that human raters scored, a long process of thumbs-up and thumbs-down meant to make it more helpful, more agreeable, less likely to say something strange. This is the stage that makes a chatbot pleasant to talk to, and it works. But it has a side effect, and the side effect is the favorites.
When a human rater is handed two perfectly fine answers and asked which is better, they tend, without noticing they’re doing it, to give a slightly higher score to the one that sounds familiar and expected. Not dramatically higher. Just a nudge. The trouble is that the polishing process takes that small, quiet, barely-conscious human preference and sharpens it. It doesn’t gently lean the model toward the typical answer; on a narrow question it compresses nearly all the odds onto it. A faint human tilt goes in, and a near-reflex comes out. The 2025 paper that worked this out, “Verbalized Sampling” by Zhang and colleagues at Northeastern, Stanford, and West Virginia University, gives it a name worth keeping: typicality bias. Their cleaner phrasing is that when several answers are equally good, this bias acts as a tiebreaker that sharpens the polished model onto a single favorite.
So when you ask a chatbot for a random number, no die gets rolled. The model is quietly answering a different question instead: what number would a person most likely write down here? And the polishing step has trained it to answer that question with very little wobble. As the writer Ian Leslie puts it, drawing on the research, a person asked for a spontaneous number tends to choose one that looks like a properly random choice. The model learned that performance, the look of randomness rather than the thing itself.
The model doesn’t merely inherit the human bias. It amplifies it. When researchers asked 558 people to pick a number from 0 to 9 back in 1976, seven came up about 28% of the time, against the 10% you’d get from genuine chance. People do lean on 7. But people lean; current models lunge. The same 7 that humans reach for a little under a third of the time is the answer GPT-5.5 and Claude gave us every single time. The polishing step takes a faint human quirk and holds a magnifying glass to it.
Fix one: ask for the whole menu
If you want variety from a chatbot, stop asking it for one answer.
A request for a single answer collapses, every time, onto the model’s one favorite. A request for the spread behaves differently. If you ask the model to lay out many options and, for each one, a rough estimate of how common or expected that choice is, you’re asking it to reach past its favorite and describe the whole range it learned in stage one. Then you pick from the unlikely end yourself. This is the technique from the Verbalized Sampling paper, “How to Mitigate Mode Collapse and Unlock LLM Diversity” by Zhang and colleagues, and the useful surprise is that you need nothing fancy to use it.
Here is the prompt, ready to paste into ChatGPT, Claude, or Gemini:
Give me 15 dog names, and for each one a rough estimate of how common or typical a choice it is, as a percentage. Then pick one for me from the less common end of the list.Swap “dog names” for story ideas, business names, plot twists, paint colors, anything where you want range. The paper’s own version of this prompt is more elaborate, with probability tags and a JSON structure, because it was written for developers calling the model through an API. We tested the plain-language version above, the one with no tags and no code, and it produces the same effect in an ordinary chat window. You can skip the formal one.
The before-and-after is clean. In our plain “suggest a dog name” runs, each model repeated its single favorite over and over. With the menu prompt above, GPT-5.5 and Claude Opus 4.7 each produced six different final picks across twelve runs, every one of them landing at the uncommon end of the list. Asked plainly, ChatGPT gives you a name like Biscuit. Asked for the menu, it builds the whole spread and hands you Bramble.
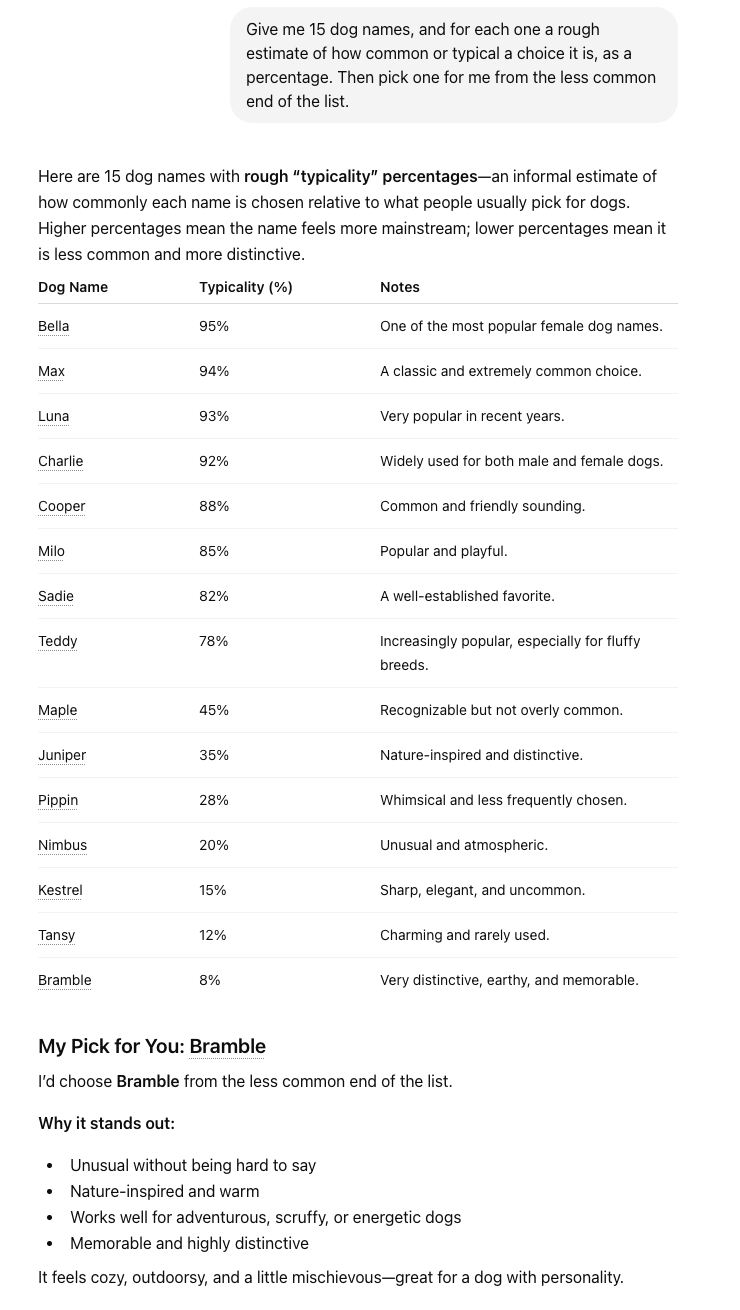
That’s the run shown above. ChatGPT laid out fifteen names with a typicality percentage on each, a clean gradient from Bella at 95% down through Maple at 45% and Kestrel at 15% to Bramble at 8%. Then it picked Bramble, “from the less common end of the list,” and explained that the name is “unusual without being hard to say.” Fifteen options sorted by how ordinary each one is, and a defensible pick from the rare end, all from one pasted sentence.
One limit, because overselling this would be its own kind of dishonesty. Asking for the menu reliably breaks the model off its number-one default and surfaces the uncommon options it normally hides. It doesn’t guarantee an even spread. On the number task, Claude didn’t flatten out; it simply moved its collapse, going from “7 every time” to “1” in most runs. On dog names, Gemini found the uncommon end and then parked there, returning the same rare name almost every time. So treat this fix as a better menu, not a fair dice roll. It widens the range of what you see and pulls you toward the interesting end, and then you still cast your own eye over the list and choose. For brainstorming and naming, where a human was always going to pick the winner anyway, that’s exactly the right shape. For a genuine one-shot draw, it isn’t, and that’s what the second fix is for.
Fix two: a fair pick from your own list
Sometimes you don’t want a menu. You have a list already, and you want one item off it, fairly drawn: eight names for who gets the last concert ticket, four people for who does the dishes, five restaurants and a table that can’t agree. You want the AI to act like a hand reaching into a hat, not like a waiter who keeps recommending the same dish.
The fix is to give the model a real source of wobble and a mechanical way to map it onto your list. It comes from “String Seed of Thought” by Misaki and Akiba at Sakana AI, accepted to the ICLR 2026 conference, and the idea is two steps bolted onto your own options. First, the model generates a long random-looking string of characters. Then it derives the pick from that string with a bit of arithmetic. The paper leaves the exact arithmetic to the model; the version we tested spells it out: add up the character codes (every letter and symbol has a number behind it), divide by the number of options you gave it, take the remainder, and that points at one item on your list. The reason this works is the reason it’s a little bit clever. The instruction “make up a random string” is generic. It doesn’t carry the model’s baked-in favoritism the way “pick a name” does, so the string genuinely varies from run to run. Then the arithmetic faithfully passes that variation straight through to which item it lands on.
One thing to get right before the prompt. The Sakana paper writes its instruction as a system prompt, a setting developers configure behind the scenes. A normal chat window has no box for that, so if you copied the paper’s framing you’d be handed a fix you can’t perform. The version below is one ordinary message you type into the chat like any other, and it works that way. Paste your own list in place of the names:
Here are my options: 1. Alice 2. Ben 3. Carmen 4. Dev 5. Erin 6. Finn 7. Grace 8. Hugo. First generate a random 20-character string of letters, digits and symbols. Then use that string to pick one fairly: add up the character codes, take the remainder when divided by 8, add 1, and that's the option number. Show me the string, the math, and which name it picked.Change the eight names to your own, and change the “8” to however many options you have. Because you asked the model to show its work, it does, and watching it is half the value.

The run shown above is Claude Opus 4.7 working that exact prompt. It generated the string %;CaAyq5ZIkp("#m;s!g, listed the numeric code of every character, added them to 1,522, divided by 8, and reported a remainder of 2. Two plus one is three, and option three on the list is Carmen. You can see the whole pick being assembled and then spent, one arithmetic step at a time. Across our live runs the spread held up: on an eight-name list, GPT-5.5 returned six of the eight names over ten runs, and a smaller four-name list for who cooks dinner spread across the names the same way. The naked ask gives you one favorite forever. This gives you a draw you can watch happen.
Two caveats. The first is that the arithmetic has to be done correctly, and this fix leans on the model being able to do it. The Sakana researchers found it works best on capable, reasoning-grade models and can fail on very small ones that botch the math. ChatGPT, Claude, and Gemini are all comfortably past that bar, and in the run above Claude ran the calculation through its code tool, so the math is exact. If your chatbot has a “thinking” or “reasoning” mode, turning it on makes the result steadier still. The second caveat is the subtler one. This fix spreads the pick far better than the naked ask, but it isn’t a perfectly fair draw, and the reason is the same typicality bias from earlier. When you ask a model to invent a “random” string in plain conversation, the string isn’t perfectly random either; the model has gentle favorites among characters the same way it has a favorite number. The bias doesn’t vanish under this fix. It climbs one rung, from “pick a number” to “make a random string,” and the string varies enough to spread your pick well without spreading it evenly. Good enough for who does the dishes. Not good enough for anything with money on it.
Which one to reach for
Two fixes, two jobs, and it’s worth being plain about which is which.
Reach for the menu prompt, fix one, when you want varied ideas and a human is going to make the final call: brainstorming names, generating story seeds, asking for options. It widens what the model shows you and pulls you toward the uncommon end. Reach for the list-and-string prompt, fix two, when you have a set of options and you need one of them drawn fairly with nobody curating the result: a raffle, a tie-break, settling who takes out the trash. It builds a source of wobble and maps it onto your list.
And then there’s the case for neither. Both fixes make a chatbot substantially better at this, and neither makes it a true random-number generator. The String Seed of Thought paper is careful about its own claim: the technique approaches the behavior of a real random generator, the kind built into a spreadsheet. It doesn’t equal one. So if money, security, or a fairness that genuinely matters is on the line, don’t use a chatbot’s idea of random at all. Ask it instead to write you a tiny script that calls a real random function, which ChatGPT and Claude can both run for you, or just use a site like random.org. A pasted sentence is good enough for picking who washes up tonight. It isn’t good enough for picking a lottery winner.
It is also fair to ask whether any of this matters. Most of the time, the typical answer is the one you wanted. Ask for a vegetable to put in a soup and “carrot” is a perfectly good answer; the model handing it to you instantly is a feature, not a failure. People converge on the familiar too, and we mostly don’t mind. These two fixes aren’t a new way to talk to AI all day. They’re tools you reach for in the specific moments when typical is exactly the wrong thing: when “carrot” is useless because you needed the vegetable nobody thinks of, or when the draw has to be fair and not just convenient.
What the seven was telling you
The seven was never random. It was the model showing you, very precisely, what a person is most likely to say, which is a genuinely useful thing for a chatbot to be good at and an actively unhelpful one when you wanted a surprise. Now you can tell the two apart, and you’ve got a sentence for each: ask for the whole menu when you want range, hand the model your list and a random string when you want a fair draw.
This site’s content pipeline uses the menu trick itself to brainstorm article ideas, reaching for the less crowded end. This piece came off that end of the list.