On 2026-04-02, Andrej Karpathy posted a tweet about how he uses LLMs. He called the pattern “LLM Knowledge Bases” and described a small markdown directory the model writes for him while he reads. Two days later he turned it into a gist. The tweet has done 21 million views since. The gist became the file people paste into Claude Code or Codex when they want an agent to start maintaining a wiki for them.
The pattern is not new in spirit. People have built personal wikis for twenty years and abandoned most of them. What’s new is who does the bookkeeping. In Karpathy’s framing the LLM writes and maintains every page, and the human’s job shrinks to sourcing, asking questions, and reading the result. The wiki is “a persistent, compounding artifact” because the synthesis is kept current at ingest time instead of re-derived per query.
That’s the pitch. The interesting question is whether it survives contact with how you actually work, and which version of “set it up” is worth a Saturday.
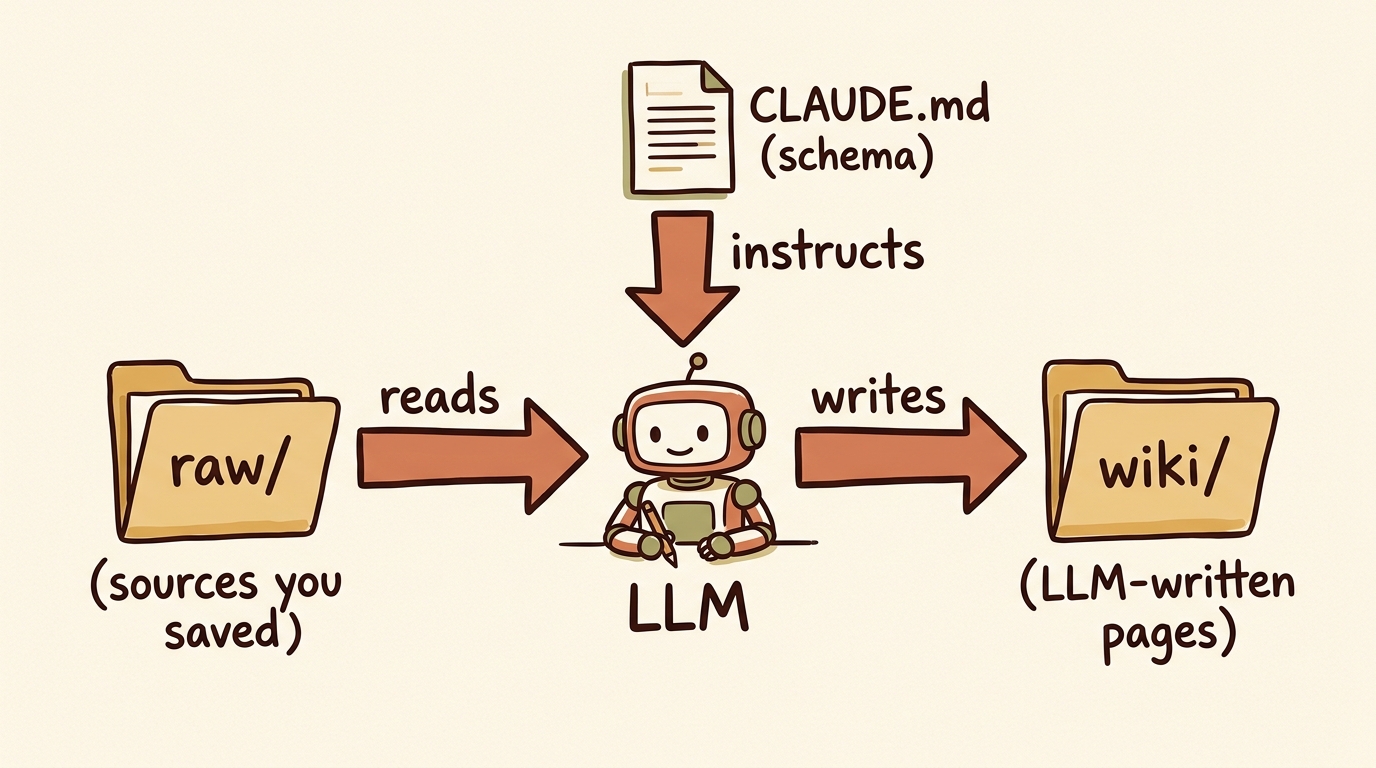
What it actually is, mechanically
Three layers do the work: a folder of raw sources you never edit, a folder of wiki pages the LLM owns, and a schema file that tells the agent how the two connect.
Raw sources. A directory of files you collect. Articles you clipped, papers you downloaded, transcripts you pasted, images. These are immutable. The LLM reads from them but never edits them. Karpathy uses raw/; most community implementations follow the convention.
The wiki. A directory of markdown files the LLM writes. Entity pages, concept pages, summaries, an index, a chronological log. The LLM owns every file in here. You read them; you don’t edit them. If you find yourself reaching for the keyboard to fix a page, you’ve slipped out of the pattern.
The schema. A single configuration file (CLAUDE.md for Claude Code, AGENTS.md for Codex) that tells the agent how the wiki is structured, what conventions to follow, what to do when you drop a new source in raw, what to do when you ask a question. This is what makes the agent a wiki maintainer instead of a chatbot. It’s the only file you and the agent co-author over time.
Karpathy’s one-line metaphor for the whole thing: “Obsidian is the IDE; the LLM is the programmer; the wiki is the codebase.” If that maps cleanly onto how you already use a markdown editor and an agent, you have most of the setup already.
The mechanism that matters is what happens at ingest. When you drop a new source into raw, the agent doesn’t just summarize it. It reads it, updates the existing entity pages that the source touches, revises the topic summaries, notes contradictions with what older sources said, and updates the index. Karpathy reports a single source touches ten to fifteen pages. Wyndo’s Obsidian implementation reports five to fifteen. The exact count isn’t load-bearing; the cross-update behavior is.
This is where the compounding lives. RAG retrieves chunks at query time and stitches them. The LLM Wiki keeps the synthesis written down, current, and cross-linked, so the next question lands on a knowledge base that already integrated the last thing you read.
A workflow, not a product (yet)
Karpathy’s gist is explicit that the idea is abstract. He calls it “an idea file, it is designed to be copy pasted to your own LLM Agent.” The agent fills in the specifics with you. There is no install step, no canonical directory structure, no required schema. The closing line of his tweet reads: “I think there is room here for an incredible new product instead of a hacky collection of scripts.” Translation: he’s running the hacky collection of scripts.
That’s the realistic starting state. The community implementations that have emerged in the weeks since are bets on what the product looks like. Pratiyush’s llmwiki ships sixteen lint rules, twelve MCP tools, four-factor confidence scoring, five lifecycle states, and an activity heatmap. Michael Manfre’s wiki-keeper is a Claude Code plugin that sanitizes web clips against prompt injection. Aaron Fulkerson’s “Exo” is a production system with twenty-six skills and fourteen MCP servers feeding live data from Gmail, Slack, HubSpot, and his WHOOP biometrics into an Obsidian vault. Fulkerson, who co-built MindTouch from 2006 to 2010, describes the experience as “building a wiki again,” twenty years later, with agents holding the pen.
None of these is the canonical implementation. The canonical implementation is a markdown folder and a schema file. Everything else is preference.
The position
Yes, but with a caveat that decides whether you waste a weekend.
The pattern pays off if the wiki is the side effect of work you’re already doing with an agent. You ask Claude Code to read a paper. The schema says: when you read something, also file the entities, update the concept page, note the contradiction, append to the log. The wiki grows while you ask the questions you’d be asking anyway. You barely notice the maintenance because you didn’t do any maintenance.
The pattern does not pay off if you set up the wiki as a project. The personal-wiki abandonment curve is real and was real before LLMs. HN commenter jbjbjbjb captures the modal outcome: “I remember the personal wiki was a bit of trend 5 years ago but it kind of died because it had an unclear purpose for the most part. I kept one but never really referred to any of the notes and then just went back to a paper and to do list.” LLM ownership of the writing fixes the bookkeeping cost. It does not fix the reading-it-back problem. If you wouldn’t open the wiki in a normal week, the LLM writes pages no one reads. HN commenter mplappert called this what it is: “people using AI to do an immense amount of busywork and then never look at it again. Colossal waste.”
The decision rule the pattern earns: if you already have an agent open most days and a markdown folder you tolerate, set it up. If you’d be installing Obsidian and learning a CLI to maintain a wiki, don’t. The pattern needs the rest of your workflow to already be there.
Three setups, ordered by effort
These are ordered from least setup to most. Pick the one that matches your current state.
One. Drop a schema in front of a vault you already have. Copy Karpathy’s gist into a new file in your existing markdown directory or Obsidian vault, then ask your agent to convert it into a working CLAUDE.md for that specific vault, naming where raw/ lives, where wiki/ lives, and how to behave on ingest. Total setup, fifteen minutes. The agent does the rest. The reason this works is the line buried in the gist: “your agent will build out the specifics in collaboration with you.” Karpathy’s document is meant to be a prompt. Treat it as one.
Karpathy’s gist (generic):
# LLM Wiki
A pattern for building personal knowledge bases using LLMs.
This is an idea file, it is designed to be copy pasted to your
own LLM Agent. Its goal is to communicate the high level idea,
but your agent will build out the specifics in collaboration
with you.
## Architecture
There are three layers:
- Raw sources: your curated collection of source documents.
- The wiki: a directory of LLM-generated markdown files.
- The schema: a document (e.g. CLAUDE.md) that tells the LLM
how the wiki is structured.Your CLAUDE.md (after the agent adapts it):
# Wiki maintainer
You are the maintainer of the wiki at ~/notes/wiki/.
Raw sources live at ~/notes/raw/ and are immutable.
## On ingest (new file in raw/inbox/)
1. Read the source end to end.
2. Update or create the entity pages it touches.
3. Revise topic summaries and note contradictions.
4. Update index.md and append one line to log.md.
## On query
Search the wiki first. Cite by wiki page and source filename.
File good answers back as new wiki pages.
## Lint cadence
Run a full lint pass every Sunday: contradictions, orphans,
stale claims, missing cross-references.Two. Run a weekly lint pass against whatever wiki you already have. Karpathy’s “Lint” operation is the most underrated part of the pattern. Ask the agent, on a cadence you’ll actually keep, to look for: contradictions between pages, stale claims newer sources have superseded, orphan pages with no inbound links, important concepts mentioned but lacking their own page, missing cross-references, data gaps that could be filled with a web search. The lint pass is the thing that distinguishes a wiki that compounds from one that rots. A monthly cadence is fine if weekly is too much. Skipping it entirely is how the failure modes below win.
Three. Wire the agent to your vault as a side effect of the work, not a separate maintenance task. This is the build with teeth. Add a SessionStart hook in Claude Code that pulls any new files in raw/inbox/ into the ingest queue, or a PostToolUse hook that triggers a wiki update after every research action. Pratiyush’s llmwiki documents both. If you’d rather not roll it yourself, Michael Manfre’s wiki-keeper plugin scopes itself to any vault containing a .wiki-keeper.yml marker and sanitizes web clips against prompt injection in the frontmatter; the sanitizer only keeps title, source_url, and clipped_at, which is the right default for clipped content from untrusted pages. Either path turns the wiki into auto-enrichment behind your normal session, which is Fulkerson’s design principle stated as plainly as it gets: “Every skill that reads from the vault also writes back to it.”
Stopping at the first setup gets you most of the value. The second earns its keep within a month. The third is for builders who already have hooks-and-MCP shaped opinions and want the wiki to maintain itself while they sleep.
Failure modes that actually kill these wikis
All three below are worth planning around. Karpathy’s gist names mitigations for two of them: compounding errors and index drift. The third, volume bloat, doesn’t get a tooling fix in the gist because it isn’t a tooling problem. It’s a reader-behavior problem upstream of the wiki, and the only honest answer is to decide whether you’ll actually read what gets written before you set anything up.
Compounding errors. Mehul Gupta’s argument against the pattern is the cleanest version: “Over time, a small misunderstanding can quietly spread across the system. The wiki still looks clean and structured, but inside, parts of it can be wrong.” Anand Lahoti calls the outcome “a knowledge base whose internal consistency is a lie.” Both are pointing at the same mechanism: LLM-authored summary pages get indexed alongside source documents, and over multiple ingests the summaries start citing each other instead of the raw. Karpathy’s Lint operation explicitly addresses this with “contradictions between pages, stale claims that newer sources have superseded.” Whether Lint catches it in practice depends on whether you run it. HN commenter Abby_101 names the residual risk after Lint: “Six months in, you have entries that are confidently wrong and the lint pass can’t tell which.” Lint catches contradictions; it doesn’t catch confidently-wrong-but-internally-consistent.
The mitigation that holds at scale is the one Lint can’t replace: keep the source link in the page, and don’t promote anything to “trusted” status without a human read. HN commenters ryanshrott and drewbatcheller converged on the same fix: “separating the capture layer from the promotion layer. Agents can draft freely, but anything that gets promoted to trusted status needs a human review.” If you’re using the wiki alone, this is just a habit. If anyone else is going to read it, draft-vs-promote is the structural fix.
Index drift. Karpathy’s pattern uses an index.md that the LLM updates on every ingest. TiddlyWiki’s creator (jermolene on the HN thread, self-disclosed) calls out the specific weakness. “Karpathy’s setup relies on an index.md that the LLM has to keep in sync as it adds notes,” he writes, and that sync job is “something LLMs are bad at, with staleness creeping in across sessions.” This is a real failure mode and worth knowing about. Two mitigations exist. You can have the lint pass rebuild the index from scratch instead of incrementally updating it (cheap, sufficient at the hundred-source scale Karpathy reports). Or you can replace the materialized index with a computed view, which is what jermolene proposes as TiddlyWiki’s structural answer. For builder-tier setups under five hundred sources, the rebuild-on-lint approach is enough.
Volume bloat and read-it-back. HN commenter johntash: “How do you keep llms from writing too much? I’ve built a few similar tools and systems, and they’re all way too easy for the llm to just keep documenting things to the point the whole system is a mess and becomes less useful the bigger it gets.” This is the one the gist doesn’t address. The LLM is incentivized to write; the wiki is silent feedback. If you don’t actually return to the wiki to ask questions of it, you’re paying the agent to produce write-only content. The honest mitigation is upstream of the wiki: don’t set it up if you don’t have a use for it. The pattern works for active research, ongoing book-reading, accumulating customer-call notes, deep-diving a topic over weeks. It does not work as a notes-collection ritual.
What the canonical scale looks like
Karpathy’s own active research wiki sits at around 100 articles and 400,000 words, and at that size he reports the index file alone is enough; the agent reads what it needs by following the index and the cross-links, no embedding-based RAG infrastructure required. Above that, qmd, the local BM25-plus-vector search MCP Karpathy recommends in the gist, becomes worth adding. Most first wikis live nowhere near the boundary, and the simpler setup will hold for months.
The honest case for setting it up this week
Every conversation with your agent today is a small piece of synthesis that disappears when the chat ends. The wiki is where that synthesis gets filed when you’re done. If “the agent forgets what we did last Tuesday” has become a low-grade tax on your week, fifteen minutes with Karpathy’s gist and your existing vault is the cheapest fix in the pattern’s range.
The product Karpathy hopes someone builds is real and probably worth the wait. The pattern, run as a hacky collection of scripts against tools you already have, is worth setting up before the product ships.
Image by Nano Banana 2.