Tell an AI to check its own work before handing it to you, and it will almost always tell you the work is good. Not because it’s lazy. Because it’s checking its own claims against nothing but itself.
Nobody mentions this when they tell you to “just set up an agent and let it run.” That advice was born in code, where it genuinely works, for one specific reason. When a coding AI writes a function, it runs the tests, and the result lands right in front of it: pass or fail, in writing, from a judge it can’t argue with. The loop improves each pass because each pass gets graded for free.
Knowledge work doesn’t come with tests. Point the same loop at a memo, an analysis, a weekly numbers report, and nothing checks it. The AI writes, reviews its own writing, and declares it done, and “done” just means it ran out of things to add. The loop isn’t converging on correct. It’s converging on confident.
So a loop that works on knowledge work needs the thing code gets for free: a grader, and you are the one who has to build it. The move that makes it real isn’t the obvious one. You don’t make the grader smarter, or tell it to be more skeptical. You reshape the work so the answer shows on its face, where even a checker that only sees the text can catch what’s wrong. An AI will happily help you build that grader. It just can’t be the one grading its own homework. So I asked it to try.
I gave Claude, Fable 5, Anthropic’s current flagship model, the kind of prompt you’d actually use:
I’m setting up a loop where you write my team’s weekly sales-pipeline risk summary, and I want you to check your own work against a rubric before showing it to me. Write that rubric, the pass/fail criteria the summary has to meet.
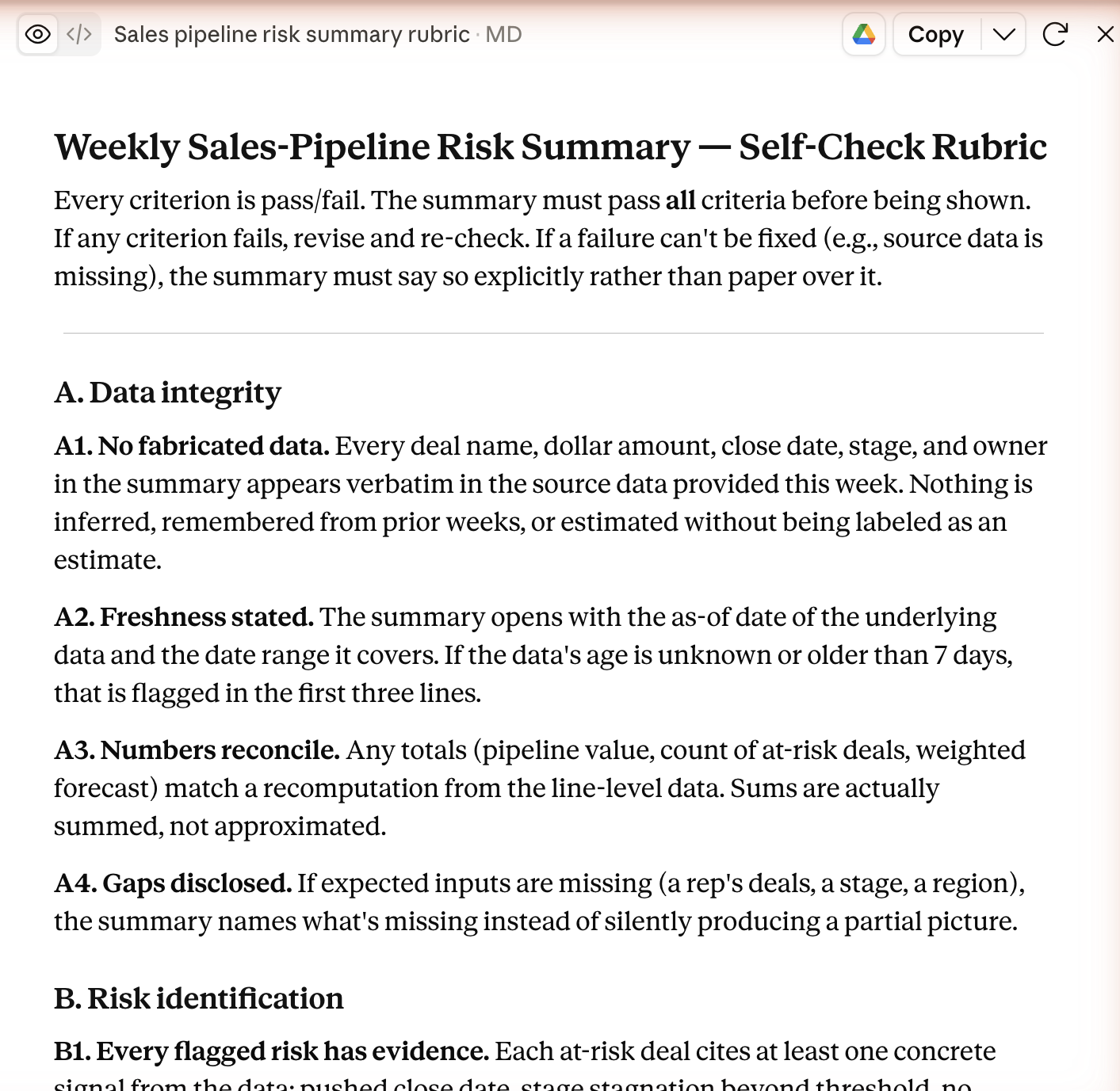
Sixteen pass/fail criteria, anti-fabrication first. It looks like a real exam, and that is the trap, because its two most important criteria can’t be checked by the thing that will run them.
Criterion A1 wants every number to appear “verbatim in the source data.” A3 wants the totals to “match a recomputation from the line-level data.” Both exactly right, and both invisible to the grader. In a real loop, the grader reads the finished summary; it doesn’t have your spreadsheet open in another window. It can’t compare anything to the source or re-add a column. So it takes a summary that swears its own numbers are right, finds no way to prove otherwise, and passes it. The loop ends. You get the wrong version, stamped approved.
This is sneakier than a sloppy rubric. A vague, hand-wavy checklist you would catch at a glance. This one is tight and professional and reads like real diligence, and its load-bearing checks quietly assume a grader with powers it doesn’t have. It looks safe. That is what makes it dangerous.
That gap has a shape, and it is the whole reason coding loops converge and knowledge-work loops drift. Simon Willison defines an agent as “something that runs tools in a loop to achieve a goal,” and the loop really is the easy part. The judge is what’s scarce. Anthropic calls the self-checking version the evaluator-optimizer, “one LLM call generates a response while another provides evaluation and feedback in a loop,” and notes it is “particularly effective when we have clear evaluation criteria.” Code is where those criteria come free. Everywhere else, you supply them.
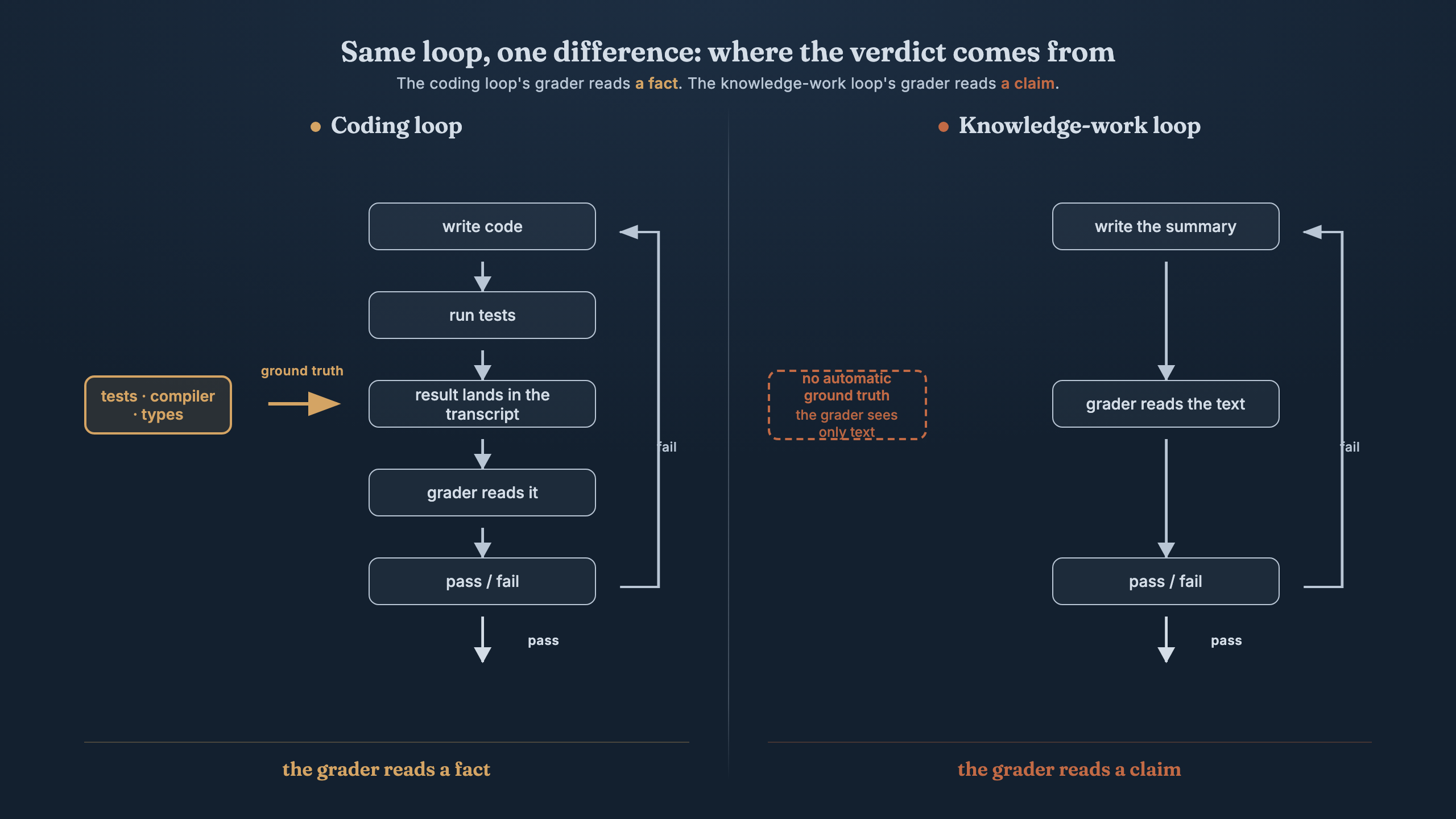
On the left, the coding loop: the tests and the compiler sit outside the model and feed a verdict back in, ground truth the next pass can read. On the right, the same loop with a hole where that judge should be, the grader reading only what the writer wrote. The toolmakers say this part out loud. Claude Code’s /goal command lets you set a condition an agent works toward, but its docs warn that the evaluator “doesn’t run commands or read files independently, so write the condition as something Claude’s own output can demonstrate.” That clause is the whole knowledge-work problem, written by the people who built the tool. The only thing in the transcript is the agent’s own claim that it did fine.
Reshape the work, not the grader
So how do you build a grader for work that has no tests? Not by sharpening the question. The instinct, when a grader can’t check something, is to make it smarter: give it more instructions, tell it to be skeptical. That’s a dead end, because the grader’s attitude was never the problem; the evidence it needs simply isn’t in front of it. You fix it from the other side. You reshape the deliverable so the answer is visible on its face.
I told the model exactly that, in the same chat:
A grader will only see the summary text, it can’t open my CRM or re-run the math. Rewrite each criterion so it’s checkable from the summary alone. For example, instead of “reports the correct total,” require an appendix table that lists every deal with an amount, and have the summary state “Sum of N deals = $X” so a checker can re-add the visible numbers.
One push. Here’s the redraft.

The model narrated the whole fix back to me. The un-checkable criterion didn’t get deleted or faked; it got moved out of the grader’s reach and relabeled “A0. (Writer-only, not gradable from text.)” In its place, the rubric now makes the summary carry its own evidence: an appendix table, one row per deal, plus shown arithmetic in the form “Sum of N deals = $X,” and every remaining criterion grew an italic Check line spelling out the mechanical test. It even wrote its own scope note, conceding the limit in plain words: a text-only grader “proves the summary is internally consistent, not that it matches the CRM.”
That inverts the obvious approach. “Is this total correct” can’t be answered from text. “Do these visible numbers add up to the stated total” can. So you reshape the work until the second question stands in for the first: make the document print the line items and their sum, and a grader that only reads text can re-add the column and catch a total that doesn’t reconcile. Anthropic’s own guidance for its Outcomes graders lands in the same place: write “explicit, gradeable criteria, such as ‘The CSV contains a price column with numeric values’ rather than ‘The data looks good.’ The grader scores each criterion independently, so vague criteria produce noisy evaluations.” Their cookbook gives the rule to hang it on: “Require concrete evidence (a fetched page, a traced formula, a file:line reference) before the grader passes anything.” Finance has done a version of this forever, with the spreadsheet check cell that reads zero only when the numbers tie, so the model isn’t done until that cell reads zero.
It works outside finance the same way. For a literature review, “cites real, relevant sources” becomes a sources table where every row carries the quoted sentence the claim rests on and a link, so the grader checks that the quote is present and supports the line, not whether the paper exists somewhere in the world. For a contract redline, “flag the risky clauses” becomes a table of clause number, quoted text, and named risk. The pattern never changes: find the criterion that secretly needs powers the grader lacks, and rebuild the deliverable so it hands over the evidence on a plate.
But isn’t it circular?
Yes, the AI writes its own test and then takes it, and the objection is sharper than it sounds, so follow it all the way down. The naive worry is that an AI will write itself an easy test. That happens, but an easy test is easy to spot. The real hazard is the one the first rubric showed: the AI writes a hard-looking test it can’t actually administer, grades itself against it anyway, and passes, and the difficulty of the test is exactly what makes the pass feel earned. A loop self-grading against a rigorous-looking rubric it can’t really check doesn’t feel reckless. It feels diligent, and confidence with a checkmark on it is harder to doubt than confidence alone.
The research is consistent, with one honest caveat: no study has tested this precise case, an AI writing a memo rubric and then grading the memo. The conclusion is reasoned from strong adjacent evidence, not measured head-on. Huang and colleagues at Google DeepMind, testing whether models can fix their own reasoning, found that “the fundamental issue is that LLMs cannot properly judge the correctness of their reasoning,” and that “after self-correction, the accuracies of all models drop across all benchmarks.” Letting the model re-grade itself, with no outside check, made it worse. And in one setting from Khullar and colleagues in March 2026, studying AI monitors that judge an agent’s actions, “self-attribution bias makes it 5 times more likely that a monitor approves a code patch that followed a prompt injection” when the action is framed as the model’s own. It is more forgiving of work it thinks is its own.
There’s a redemptive detail in that last paper, and it’s the seed of the fix. The bias comes from the work sitting in the model’s own turn, not from being told whose it is; the authors note that “explicitly stating that the action comes from the same model does not by itself induce self-attribution bias.” The leniency lives in the context, not in a label. And a context problem has a cheap solution: get the work out of the worker’s chair before you grade it.
Three things that keep it honest
That points at the three things that turn a self-built grader from circular into legitimate. Skip them and the skepticism is earned.
Ground every criterion in something outside the AI’s taste. A criterion the grader can check from the document (“the visible amounts sum to the stated total,” “the quoted sentence appears on the cited page”) is grounded. A criterion that asks the grader for an opinion (“the analysis is insightful,” “this is ready to publish”) is not, and an AI grader rewards its own taste on those every time. The measurement is stark: when researchers had models grade against rubrics, agreement with human scores held around a correlation of “ρ ≈ 0.8–0.9” on style-and-helpfulness calls but fell “below 0.3” on factual, knowledge-heavy material, the exact territory of research, finance, and legal work. Trust an AI grader on the mechanical, checkable criteria. Trust it least on the judgment calls your reader cares most about.
Grade with fresh eyes, not the worker’s. The leniency lives in the worker’s context, so move the grading out of it, the way the toolmakers do where they can. Anthropic’s Outcomes grader “uses a separate context window to avoid being influenced by the main agent’s implementation choices,” and Claude Code’s /goal hands completion to “a fresh model rather than the one doing the work.” You can do the cheap version yourself today: when a model finishes a draft, don’t ask it in the same thread whether the draft is good. Open a new chat, paste in only the deliverable and the grounded checklist, and let a clean context grade it cold. Better still, use a different model, the way Ethan Mollick describes spot-checking an analysis by having “another AI model, GPT-5 Pro, reproduce the reproduction.” As far as that second context knows, the work isn’t its own.
Stay the human who owns “good.” A self-built grader is for the boring, checkable middle of the work, not your judgment about whether the thing is any good. Two people who build these loops for a living draw the line in the same place. Hamel Husain keeps the human’s job to one call: “Did the AI achieve the desired outcome? No complex scoring scales or multiple metrics. Just a clear pass or fail decision,” and he won’t trust an AI judge until it agrees with a named human about ninety percent of the time. The economist Pedro Sant’Anna, who runs a loop that genuinely converges over his own research, scores every file zero to one hundred, halts below eighty, lets it “converge after 2 consecutive clean rounds,” and is explicit that “it is deliberately not an autonomous daemon: every loop is started by you or a skill, never on its own.” The grader handles the reconciliation. You still decide whether the memo is worth sending.
That division isn’t a hedge, it’s the honest shape. Researchers who studied AI-built evaluators found they “simply inherit all the problems of the LLMs they evaluate, requiring further human validation,” which sounds fatal until you read the companion finding from the same group: you couldn’t write the perfect rubric up front even if you tried, because of “criteria drift: users need criteria to grade outputs, but grading outputs helps users define criteria.” You learn what “good” means by watching bad drafts fail. So the real workflow isn’t “write the perfect rubric, then automate.” It’s to have the AI draft a rubric, ground it against an example you already trust, prune what the grader can’t actually check, and keep editing it as the loop shows you what you forgot to ask for.
What this actually buys you
None of this means loops don’t help. It means the help is narrower and more supervised than the autonomous-agent-team pitch suggests, and two true things sit in tension. Verification really is easier than generation, which is why any of this works; Jason Wei calls it the asymmetry of verification, “some tasks are much easier to verify than to solve,” and a grounded checklist is a tool for exploiting it. But the same essay names the catch, by way of Brandolini’s law: “The amount of energy needed to refute bullshit is an order of magnitude bigger than that needed to produce it.” Checking a sum is easy. Checking whether a market analysis is actually right can cost more than writing it did, and that part doesn’t reshape into a tidy text check. So the durable wins are the modest-sounding ones, all human-started and narrowly scoped, like the law firm one ChatGPT user described running to “check citations in a brief while signed into Westlaw,” which works precisely because it verifies against a real source instead of generating from nothing.
Discipline matters here because knowledge work hides its errors better than code does, and the feeling of progress is an unreliable witness. When METR ran a controlled trial on experienced developers, the developers “still believed AI had sped them up by 20%” afterward, while the measured result that year ran the other way. (METR’s own authors have since walked that magnitude back, so don’t quote the number as current.) The durable part is the gap between the felt speedup and the measured one, and it survived in a field that has a compiler to puncture the illusion. Knowledge work has no compiler. The grader you build is the only thing standing between “this feels done” and “this is checked.”
So automate the boring, checkable middle, the reconciliation and the citation-tracing and the does-the-table-match-the-text, and on the part that is an actual judgment call, keep a human gate by design. A loop that knows when it’s done is one you taught to show its work.
If you want to try one thing today, make it the fresh-eyes grade. Take something a model wrote for you, open a clean chat, and paste in only the deliverable plus three or four checks a reader could verify by looking: the numbers add up, every claim names its source, the recommendation follows from what’s above it. Ask it to mark each one pass or fail and quote the line it’s judging. You’ll watch a fresh context catch things the original thread waved through, and in about a minute you’ll have built the smallest honest version of the grader that knowledge work forgot to include.
(Loops that run on a schedule, drifting a little each time they fire, are a different problem with a different fix, and a separate piece.)